「日本一巨乳な風俗嬢って誰?」
「ウエスト60より太い風俗嬢って何割いるの?」
「一番多い源氏名は何?」
その疑問、データベースを作れば答えが出せます。
この連載記事では、全国のデリヘル嬢30万人以上の情報をまとめたデータベースの作り方を解説します。
~各回の内容~
第1回 データベース作成用の風俗情報サイトを選ぶ ←いまここ
第2回 デリヘルタウン全店舗のURLリストを作る
第3回 全店舗のURLリストから、htmlのソースコードを取得
第4回 htmlのソースコードから女の子の情報を取得する
もくじ
この連載記事でやること
世の中には様々な風俗情報サイトが存在します。
しかし、冒頭に挙げたような疑問は情報サイトからは知ることができません。
その理由は、風俗情報サイトには店舗ごとの女の子情報しかないからです。
冒頭に挙げた疑問の解決には、全国の嬢の統計データが必要になります。
つまり、先ほど挙げた疑問を解決するには、自分でデータを統計分析する必要があります。
そうなると当然必要になるのが、「日本の全風俗嬢をまとめたデータベース」。
そんな都合のいいものがどこかでダウンロードできればいいのですが…残念ながらありません。
答えは簡単、自分でデータベースを作ればいいのです。
風俗情報サイトには、たしかに店舗ごとの女の子情報しかありません。
しかし、全店舗の情報をかき集めてくれば、全風俗嬢のデータベースが作れるはずです。
この連載記事では、以上の考え方でデリヘル嬢のデータベースを作っていきます。
第1回となる今回は、これから作るデータベースの作成方針について説明していきます。
どんなデータベースを作るの?
デリヘルタウンに登録されている全デリヘル嬢のデータベースを作ります。
データベースというと大層なものに聞こえますが、実際は1つのcsvファイルに全デリヘル嬢の情報をまとめるだけです。
本記事で作るもの
言葉で説明するよりも完成品を見ていただいたほうがわかりやすいかもしれません。最終的にできあがるものは以下のようなファイルです。
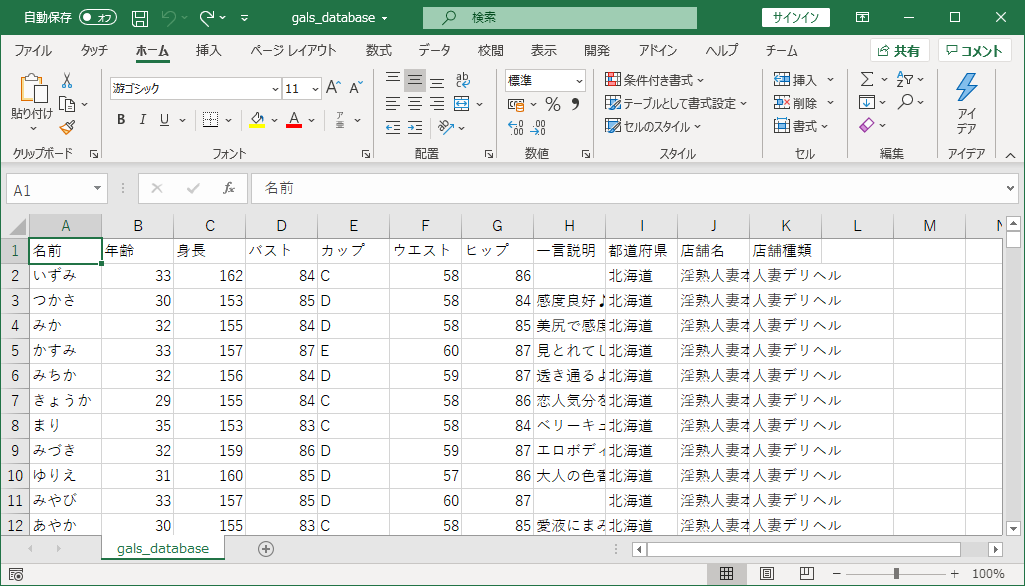
上述のCSVファイルを作るのがこの連載記事のゴールです。
これさえできれば、ちょこちょこと数十行のプログラムを作って分析が可能です。
データ分析の例
せっかくなので、どのように分析するかという例も挙げておきましょう。
例えば以下のプログラムを作れば、出来上がったデータベースを読み込んで「カップ」列を円グラフと表で出力できます。
# 本プログラムの目的:
# デリヘル嬢のバスト分布を円グラフで出力
# ライブラリインポート
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 円グラフのフォント設定
fp = FontProperties(fname=r'C:\WINDOWS\Fonts\meiryob.ttc', size=16)
font = {"family":"MS Gothic"}
plt.rc('font', **font)
# csv読み込み
gal_df = pd.read_csv('database/gals_database.csv')
# カップの記載がある嬢のみ抽出
valid_df = gal_df.query('カップ != "-"')
# 円グラフでは大まかな割合しかわからない。
# 正確な数を把握するためコンソール上にA~Zカップの女の子の数を表示する
print('\tカップ\t人数')
cups = [
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N',
'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'
]
for cup in cups:
num = len(valid_df.query('カップ == @cup'))
print( '\t%s\t%d' % (cup, num) )
# それぞれのバストの嬢の数から円グラフを作る
label = ['Aカップ', 'Bカップ', 'Cカップ', 'Dカップ', 'Eカップ', 'Fカップ', 'Gカップ','Hカップ以上']
data = []
data.append( len(valid_df.query('カップ == "A"')) )
data.append( len(valid_df.query('カップ == "B"')) )
data.append( len(valid_df.query('カップ == "C"')) )
data.append( len(valid_df.query('カップ == "D"')) )
data.append( len(valid_df.query('カップ == "E"')) )
data.append( len(valid_df.query('カップ == "F"')) )
data.append( len(valid_df.query('カップ == "G"')) )
data.append( len(valid_df) - sum(data) )
# 円グラフ出力の設定
plt.pie(data, labels=label, autopct="%1.1f%%")
plt.title('全国のデリヘル嬢のバスト分布', fontproperties=fp)
# 円グラフ出力
plt.show()
このプログラムを実行すると、以下のような図が出力されます。

あわせて、以下の表が出力されます。
(見やすいようにhtmlの表に書き直しています)
|
|
分析結果から何がわかるか?
話は脱線しますが、分析結果の考察もしてみましょう。
ここでは冒頭で挙げた、国内最大のおっぱいという視点で考察してみます。
私は、「きゃんでぃドロップス在籍の五十嵐ゆいさんが最大のバストである」という仮説を立てていました。
結論から言うと、その仮説は正しいことが分析によってわかりました。
参考までに、五十嵐ゆいさんのバストは172cmのQカップです。
デリヘルタウンの情報は少し古いプロフィールになっているようですね。
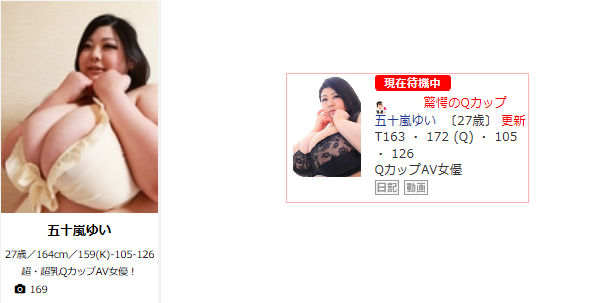
右がシティヘブン(https://www.cityheaven.net/tokyo/A1317/A131703/candi-drops2/girllist/)のデータを引用。
一方で、先ほどの表を見るとデリヘルタウンに登録されている最大のバストはPカップですね。
したがって、筆者の大好きな五十嵐ゆいさんはデリヘルタウン唯一のQカップとわかりました。
※他店でも入力漏れなどある可能性はありますが、全部検証するのも大変なのでそこまでは考えないことにします。
それは国内最大の爆乳を味わった体験だと思うと、実に感慨深いものです。
話はそれましたが、大体のイメージはついたかと思います。
それでは早速データベースを作りましょう…と言いたいところですが、それは次回にします。データベース作成前に検討すべきことがあるので、今回はその検討をしていきましょう。
事前検討1 データ取得元のサイトを選定しよう
繰り返しになりますが、今回はデリヘルタウンに登録されている女の子の情報をかき集めてデータベースを作成します。
「なぜデリヘルタウンなの?ほかのサイトじゃダメなの?」と思う人もいるでしょう。
その理由は、検討の際に2つの条件を重視したからです。以下では、その条件についてお話しします。
条件1 メジャーなサイトであること
作成するのがデータベースである以上、できるだけたくさんの女の子のデータが欲しいところです。そして、日本全域の風俗店が掲載されていることが望ましいです。
一部地域の店舗しか載っていないサイトだったり、掲載店舗数が少なかったりすれば、偏ったデータになってしまいますからね。そういう理由で、最も望ましいのは「シティヘブン」、次点で「デリヘルタウン」と自分は考えました。
ヘブンであればデリヘル以外にもソープなどの情報も載っているので最適かと思ったのですが、2つ目の条件に合わなかったため廃案となりました。
条件2 解析しやすいこと
「解析しやすさ」はサイトのhtmlソースコードから判断します。windows10なら、サイト上で右クリックして「ソースの表示」をクリックすれば見ることができますね。
データベース作成の際はhtmlソースコードから情報を抽出するので、欲しい情報がソースコードのどの部分に書かれているかを把握する必要があるのですね。
ヘブンは、お店検索をしたときにページ下部に表示される「もっと見る」がクセ者でした。「もっと見る」によって表示される情報は、ソースコードの中に無いのです。
つまり、ヘブンでは情報量が多いと「もっと見る」に隠れてしまい、情報が取得できないことがわかりました。
おそらく解決方法はあるのでしょうが、自分はスキルがないので断念。解析しやすそうなデリヘルタウンを選択しました。
先駆者様との選択の違い
実は「風俗嬢を分析する」という分野には先駆者様がいます。
自分は今回の分析を思いついたときに「これ面白そうじゃね?」とはしゃいだものですが、
同じようなことを考える人はいるものですね…。
そして、その先駆者様は「kaku-butsu」というサイトを使ってデータを収集したようです。
先駆者様のように「店舗No.1~3の嬢のみピックアップ」ということをやりたいのならおそらくデリヘルタウンだとできないでしょう。
一方で、今回のように「単純に全国の嬢すべてのデータが欲しい」というのなら、デリヘルタウンで十分というのが自分の考えです。
このように、サイトの選定は目的を明確にしたうえで検討するのが重要です。
事前検討2 デリヘルタウンの構成を理解しよう
データベースを作るためには、「女の子一覧」ページのhtmlソースコードが全店舗分必要です。
ただ、URLがわからないとhtmlソースコードは取得できません。
そのため、最初にやるべきは「女の子一覧ページのURLリストを作るプログラム」の作成です。
このプログラム、詳しくは第2回で話しますがトップページからリンクをたどるアルゴリズムになります。
したがって、どのようにリンクをたどれば女の子一覧ページにたどり着くかを理解する必要があります。
これは言い換えれば、サイト構成を図に落とし込む作業です。
地道に調査して自分が作成した図がこちら。
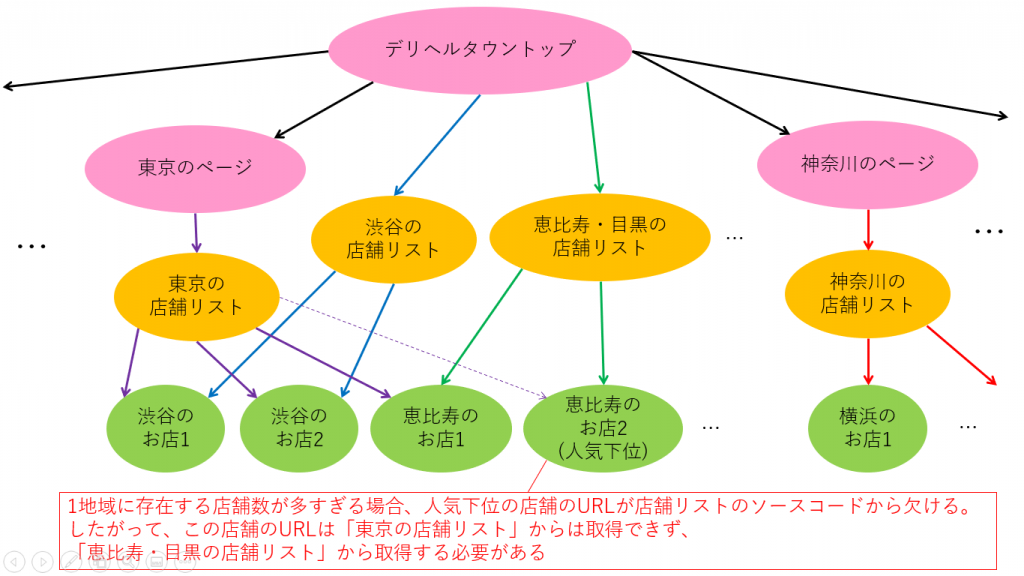
赤字で注意書きがあったりと、なんかゴチャゴチャしていますね。
細かい話は、次回プログラミングしながら見ていくとしましょう。
この図を参考にすれば、実際にプログラムが作れそうですね。次回からはゴリゴリとプログラミングをしていきます。
最後に
以上、今回はデリヘルタウンのサイト構成まで理解を進めました。
次回はこの情報をもとに「女の子一覧」ページのURLリストを作成していきます。
次の記事は以下からどうぞ