この連載記事では、全国のデリヘル嬢のデータベース作成を目標にプログラミングをしていきます。
本記事は、連載記事の第2回に当たります。そもそも、できあがるデータベースはどんなものか?データベースを作るとどんなことができるのか?それについては、前回の記事をご覧ください。
前回の記事
~各回の内容~
第1回 データベース作成用の風俗情報サイトを選ぶ
第2回 デリヘルタウン全店舗のURLリストを作る ←いまここ
第3回 全店舗のURLリストから、htmlのソースコードを取得
第4回 htmlのソースコードから女の子のデータベースを作成
もくじ
100文字でわかる、前回のあらすじ
デリヘルタウンの「女の子一覧」ページをかき集めて全デリヘル嬢のデータベースを作ることにしました。
全店舗分の「女の子一覧」ページにたどり着く方法を分析するために、デリヘルタウンのサイト構成を調べました。
※「女の子一覧」ページの例
https://www.dto.jp/shop/7/gals
今回やること: 全店舗のURL一覧を作ります
今回からはゴリゴリとプログラミングをしていきます。
第1回ではデリヘルタウンのサイト構成を理解するところまで進めました。
今回はデータをかき集めるための前準備として、デリヘルタウン全店舗のURL一覧を作成します。
できあがるのは、こんな感じのtxtファイルです。
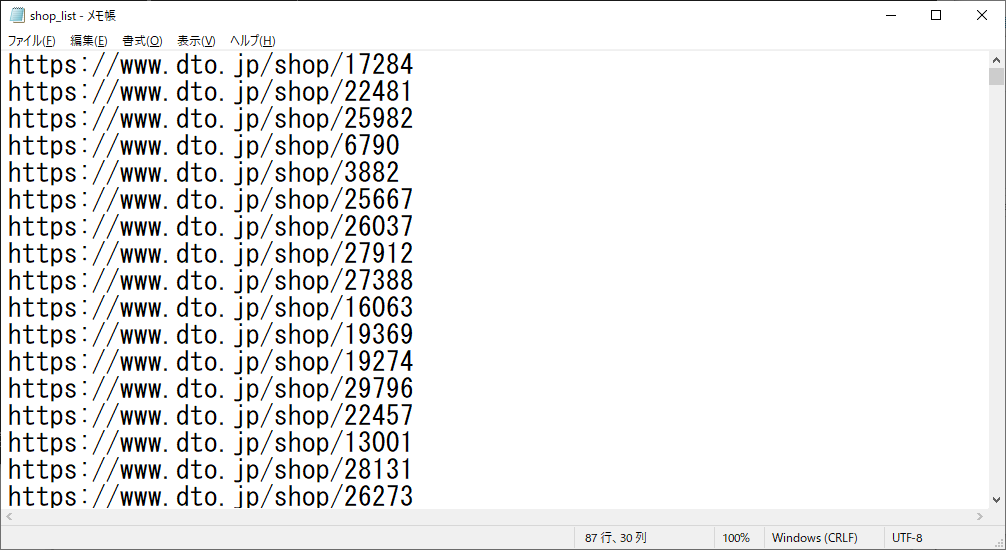
このtxtファイルが作れれば、全店舗の「女の子一覧」ページの情報をまるごと自分のPCに持ってくることができます(その方法は第3回の記事で説明する予定です)。
プログラミング環境の準備
ツールの準備
プログラムの開発は、以下の環境で行います。
OS: windows 10
使用言語: python(インストールにはAnaconda for Windowsを使用)
pythonの環境作成方法については、細かく書くとそれだけで1つの記事になってしまいます。
そのため、私が環境作成時に参考にしたサイトの紹介にとどめます。
基本的に書いてある通りに進めていけば環境作成ができるはずです。
Anaconda を Windows にインストールする手順
https://weblabo.oscasierra.net/python-anaconda-install-windows/
作業フォルダの準備
作ったプログラムを置くフォルダを用意します。適当なところに「src」という名前のフォルダを作りましょう。
また、その中に空のフォルダを3つ作ります。名前はそれぞれ、「htmls」「list」「database」とします。
図で書くと、以下のようなフォルダ構成になりますね。
- src
- htmls
- list
- database
今後作るプログラムは、すべてsrcの直下に置いていくことにします。
ステップ1: 店舗リストのURL一覧を作ろう
プログラム作成~実行
では目的のプログラムを作っていこうと思います。
前回の記事で紹介したデリヘルタウンの構成図をもとに作ります。
具体的には以下の図ですね。要するに、デリヘルタウンはトップページからリンクをたどっていけば各店舗のページにたどり着ける構成になっています。
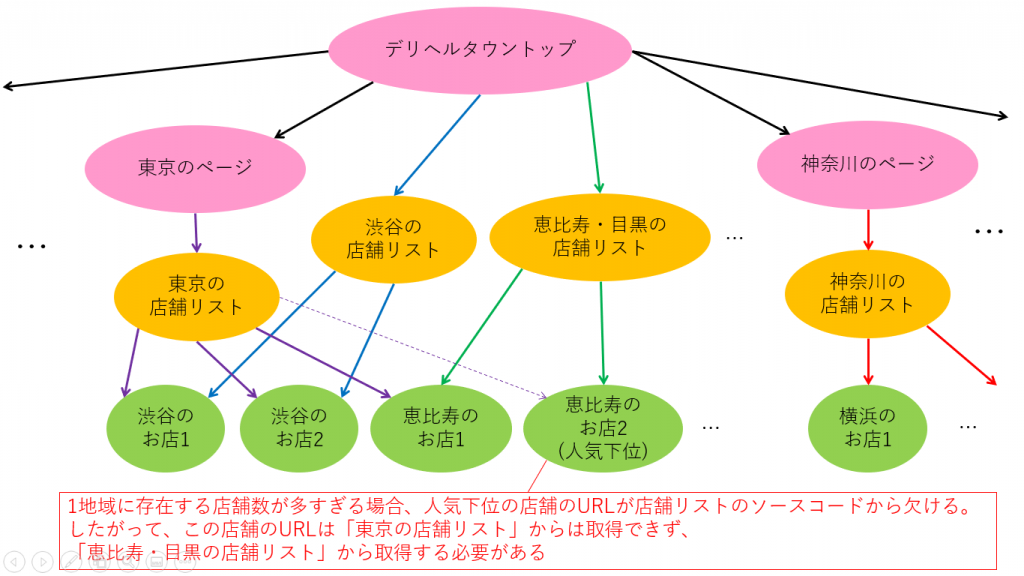
「図の見方がわからん!」という人のために、実際のURLをベースに説明しましょう。デリヘルタウントップが以下のURLにあたります。
https://www.dto.jp/
トップページ内の、例えば「渋谷」というリンクをクリックすると以下のURLに飛べますね。
https://www.dto.jp/shibuya/shop-list
これが、「渋谷の店舗リスト」にあたります。このように、上図の矢印はリンクで飛べる先を表しているわけですね。
なお、図の下部に赤字で何か書いてますが、それについては補足のセクションで説明します。
さて、最終的に必要なのは店舗のURL一覧でした。よって、緑の丸で示したページのURLが欲しいということになります。
が、その前にまずは店舗リストのURL一覧を作りましょう。図で言えばオレンジの丸で示したページですね。
最終的に欲しいのは緑の丸のURL一覧なんですが、いっぺんにゴールまで行くのは大変なので2ステップに分けて作業を進めるわけですね。
URL一覧は、pythonのプログラムによって作成します。出来上がったものがこちら。
gen_area_list.py
# 本プログラムの目的:
# デリヘルタウンのトップページにある、
# 「各地域の店舗リスト」のURLをファイルに書き出す
from requests_html import HTMLSession
import re
# デリヘルタウントップのURL
url_dto = 'https://www.dto.jp'
# デリヘルタウントップページの情報取得
session = HTMLSession()
r = session.get(url_dto)
# 以下、ファイルへの書き出し
f = open('list/area_list.txt', 'w')
for link in r.html.links:
# 取得したURLから、都道府県を表すURLだけ選別して書き出す。
# 取得するURLの例:「/hokkaido」とか「/aomori」とか。スラッシュの数で判別する
is_main_area = ( len(link.split('/')) == 2 )
if(is_main_area):
# https://www.dto.jp/を頭につけてファイル書き出し
f.write(url_dto + link + '/shop-list' + '\n')
# 取得するURLの例:「/mito/shop-list」とか「/hakata/shop-list」とか
is_sub_area = re.search('/*/shop-list', link)
if(is_sub_area):
# https://www.dto.jp/を頭につけてファイル書き出し
f.write(url_dto + link + '\n')
これを実行(※)すると、店舗リストのURL一覧が出来上がります。
(※)anaconda promptを開いてsrcフォルダまで移動し、以下のコマンドで実行すればOK
> python gen_area_list.py
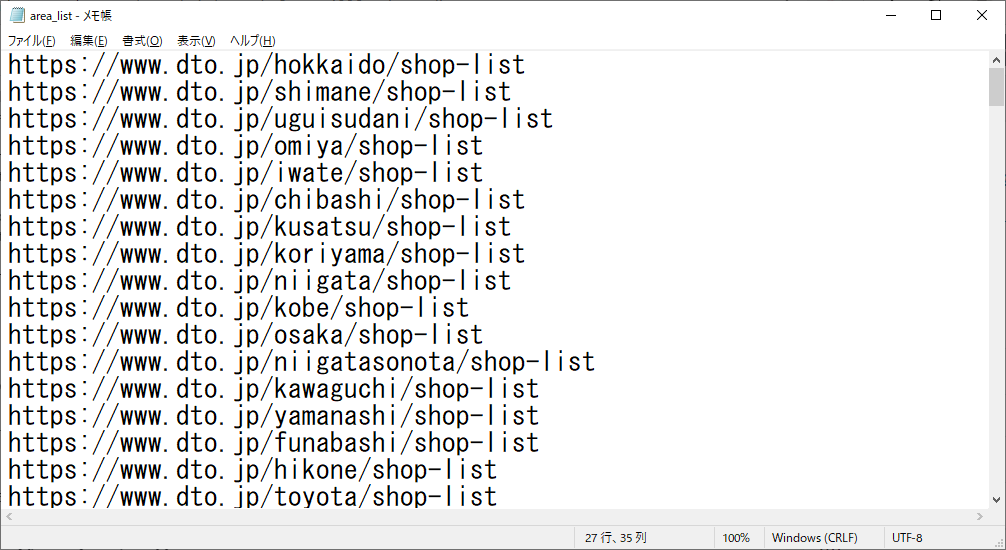
listフォルダに、area_list.txtができます。メモ帳などで開いてみて、以下のようにURLがリストされていたらOKです。
補足1: 都道府県以外の店舗リストの必要性
「東京の店舗リストあるなら渋谷とか恵比寿の店舗リストいらなくね?」と思う人がいるかもしれません。
この点について説明します。
第1回の記事で、シティヘブンを使わない理由を説明しました。
中でも大きいのが、「店舗リストからURLを取得する手法では、1ページに表示する店舗数が多すぎるとランキング上位の店舗しかURLが取得できない」というものでした。実はこの現象はデリヘルタウンでも起こるのです。
しかし、デリヘルタウンの場合、店舗が多すぎる地域は別途リンクを作ってくれています。
上の図で言えば、「東京」の店舗リストで表示しきれないお店を「渋谷」や「恵比寿・目黒」…などの店舗リストで補っているということですね。
というのが、上述の構成図でデカデカと赤字で注釈している内容です。
だからこそ、「東京」だけでなく「渋谷」や「恵比寿・目黒」などの店舗リストも必要になるのですね。
補足2: もっと簡単にURLリスト作れないの?
URL一覧が欲しいだけなのに手間かかりすぎでは…?と思う人もいるでしょう。
実は、「sitemap.xml」というファイルを公開しているサイトならもっと簡単な方法があります。
sitemap.xmlというのは、そのサイトに属するURLをリストしたファイルです。
したがって、sitemap.xmlをまるごとコピーしてくれば今回欲しかった情報が一発で手に入るのですね。
しかし、基本的に風俗サイトはsitemap.xml非公開なので、今回のような手法を使うしかありません。
この辺は非常に面倒ですね…。
ステップ2 全店舗のURL一覧を作ろう
プログラム作成~実行
ステップ1で作成したarea_list.txtを使って、緑丸のURL一覧を作ります。
作成するプログラムは、「area_list.txtに書いてあるURLにアクセスし、アクセスしたページ内にあるリンクを取得する」というものにします。
ただ、ここで気をつけねばならないのが重複の処理です。
例えば、渋谷でランキング上位の店舗は「東京の店舗リスト」からも「渋谷の店舗リスト」からも取得できます。
それを踏まえて、URLは重複して書き出さないように注意せねばいけません。
以上を踏まえて、出来上がったプログラムは以下のようになります。
「shop_list = list(set(shop_list))」が、重複書き出しを防いでいる部分になりますね。
gen_shop_list.py
# 本プログラムの目的:
# 「各地域の店舗リスト」をもとにして、
# 全登録店舗のURLを取得する
from requests_html import HTMLSession
import re
import time
# 本プログラムは実行に時間がかかる。
# そのため、進捗をコンソール上に表示するための変数を用意
num_current = 0
num_shops = sum(1 for line in open('list/area_list.txt'))
# デリヘルタウントップのURL
url_dto = 'https://www.dto.jp'
# get_area_listで作った各地域の店舗リスト
rf = open('list/area_list.txt', 'r')
# 以下、全店舗のURLをリストに詰め込む
shop_list = []
for line in rf:
# 店舗リストから各店舗のURL取得
session = HTMLSession()
r = session.get(line.strip())
for link in r.html.links:
# 取得したURLから、店舗のURLだけ選別して書き出す。
# 取得するURLの例:「/shop/30552」とか「/shop/29517」とか
is_shop = re.search('/shop/', link)
if(is_shop):
# https://www.dto.jp/を頭につけてリストに追加
shop_list.append(url_dto + link)
# サーバに負荷をかけないよう、1つのページにアクセスするごとに1秒停止
time.sleep(1)
# 現在の進捗を表示
num_current += 1
print( '\r' + '現在の進捗: %03d / %03d ' % (num_current, num_shops), end='' )
# 以下、ファイルへの書き出し
# shop_listには、店舗のURLを片っ端からぶち込んでいる。よってURLが重複していることがある。
# そのため、setコマンドによって重複をなくす。
shop_list = list(set(shop_list))
# 書き出し先のファイル
wf = open('list/shop_list.txt', 'w')
# リストをファイルに書き出し
for shop in shop_list:
wf.write(shop + '\n')
これを実行(※)すると、店舗リストのURL一覧が出来上がります。
(※)anaconda promptを開いてsrcフォルダまで移動し、以下のコマンドで実行すればOK
> python gen_shop_list.py
listフォルダの中にshop_list.txtができます。
ステップ1と同じようにメモ帳などで開いてみて、以下のようにURLの一覧が書かれていれば成功です。
補足: shop_list.txtは「女の子一覧」ではなく「店舗トップページ」のURL一覧である
今回の記事の最終成果物である、「shop_list.txt」は、店舗トップページのURLです。
あれ?欲しいのは「女の子一覧」ページのURLじゃなかったの?と思う人もいるかもしれませんが、そこはご安心ください。
女の子一覧ページにアクセスしたいときはそれぞれのURLの後ろに「/gals」をくっつければ「女の子一覧」ページのURLとなります。
最後に
以上、今回はデリヘルタウン全店舗のURLリストを作りました。
次回はこのリストをもとに「女の子一覧」ページのhtmlソースコードを取得していきます。
次の記事は以下からどうぞ