この連載記事では、全国のデリヘル嬢のデータベース作成を目標にプログラミングをしていきます。
本記事は連載記事の第4回(最終回)に当たります。
ここに至るまでの手順については第1~3回の記事をご覧いただけると幸いです。
前回の記事
~各回の内容~
第1回 データベース作成用の風俗情報サイトを選ぶ
第2回 デリヘルタウン全店舗のURLリストを作る
第3回 全店舗のURLリストから、htmlのソースコードを取得
第4回 htmlのソースコードから女の子のデータベースを作成 ←いまここ
もくじ
前回までのあらすじ
デリヘルタウンに登録されている全デリヘル嬢のデータベースを作ることにしました。
方針としては、店舗ごとに存在する「女の子一覧」ページから情報を抽出します。
前回時点で、「女の子一覧」ページのhtmlソースコードを自分のPCに保存するところまで終了しました。
※「女の子一覧」ページの例
https://www.dto.jp/shop/7/gals
今回やること: htmlソースを使ってデータベースを作成します
今回でいよいよ最後です。
全デリヘル嬢のデータベースを完成させます。
方法としては、デリヘルタウンの「女の子一覧」ページのhtmlソースコードから情報を抽出して作ります。
抽出元に必要なhtmlソースコードは前回自分のPCにコピーしたので、それを使用する方針です。
実際には、以下の図のようなファイルが出来上がるわけですね。
事前検討: 除外すべきデータを考える
今回はプログラムを作る前に、ちょっと事前検討を行いましょう。
先ほど、htmlソースコードから情報を抽出すると言いました。
しかし、実際に抽出元となる「女の子一覧」ページを見てみると、たまに変なデータがあるんですね。
では、どういうものが「除外すべきデータ」か、実例を見てみましょう。
同時に、「どんなプログラムならそういうデータを除外できるか」も分析していきます。
※お店の評判を落とさないよう、あえて店名は出しません。
除外すべきデータの例1: スリーサイズが間違っている
これはわかりやすいですね。例えば下の図。
バスト838という超爆乳の女の子になっています。
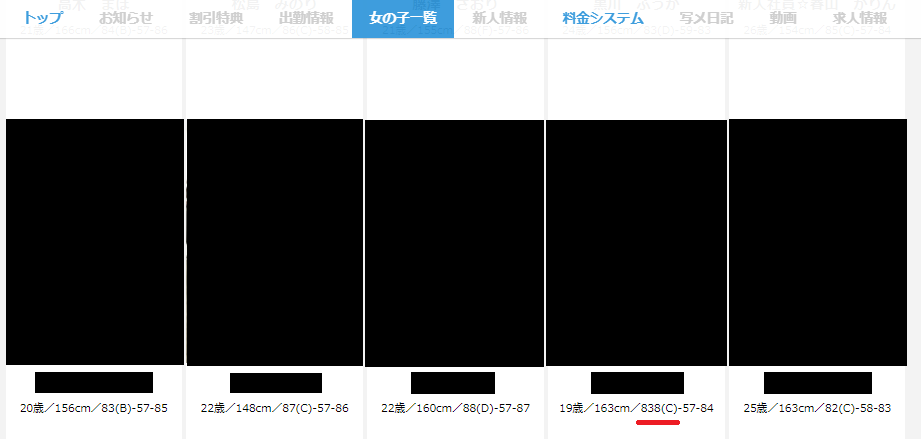
デカければデカいほど好きな自分としては、いつかこんなおっぱいに押し潰されたいものです。
とはいえ、当然これは書き間違いですね。
バストカップがCなので、恐らく83か88の誤記でしょう。
まあこういうミスって指摘されないと気づけないですよね。
自分もよくやらかすので気持ちはわかります。
とはいえ、2か月前に見た時も同じ状態だったので、
そのうちお客さんから何か言われそうなものですけどね。そもそもデリヘル嬢の公称スリーサイズは誰もあてにしていないのだろうか
例えばバストなら、「40以下または200以上の場合は登録しない」という感じですね。
今回は以下を満たすデータだけ登録することにしましょう。
- 年齢:15~100
- バスト:40~300
- ウエスト:40~300
- ヒップ:40~300
除外すべきデータの例2: イベントが女の子として扱われている
これがかなり厄介で、以下の画像のようなケース。

なお、ケース1とケース2は別々のお店です。
割引イベントの紹介なんですが、それが女の子として登録されていますね。
このケースはかなり多くのお店で見受けられます。
とはいえ、スリーサイズが「?」だったりすることも多いです。
そういう場合は、先ほどと同じ方法が使えます。
しかし、ケース1は、まるでスレンダーな女性のようなスリーサイズになっています。
スリーサイズをどう登録するかはお店によってまちまちなのですね。
そうなると、名前で判断するしか方法がなくなります。
とりあえず、今回は名前に以下が含まれているときはデータベースに登録しないことにします。
- 割
- コース
- 円
- キャンペーン
- ツイッター
- LINE
- 日記
なお、この手法では「円谷」とか「あいちゃん★SMコース歓迎」みたいに、
たまたま条件に合致する登録名の女の子も除外されます。
統計処理をする場合はそこまで影響がないので、今回は気にしないことにします。
今回の対策はどれくらい効果があるのか
今回お伝えした手法によって、例1にあたるデータはバッチリ除外が可能です。
一方で、例2にあたるデータは完全には除外しきれません。
割引イベントの名前はお店ごとにまちまちなので、「このワードを含むとアウト」という分析方法だと限界があるのですね。
厳密に選別するには、データベース作成後に目視で1行ずつチェックするしかありません。
今回は面倒なのでそこまでは行わないことにします。
変なデータを除外できているかは、実際にデータベースを作ってみて効果を分析しました。
確認の結果、上で述べた工夫を入れると、変なデータは0.1%くらいしか紛れ込まないことが分かりました。
これなら統計処理してもそれほど大きな誤差は出ないでしょう。
今回の対策はそれなりに機能していると分析できます。
プログラム作成~実行
では、プログラムを作っていきましょう。
「htmlコードから情報を抽出してcsvファイルにまとめる」という機能を持ったプログラムになります。
実際に書いたプログラムは以下の通りです。
gen_database.py
# 本プログラムの目的:
# 「女の子一覧」ページのソースコードをもとに、
# 全デリヘル嬢のデータベースを作る
import bs4
import pandas as pd
import numpy as np
import re
import glob
# 有効な情報かどうかを判定
def is_valid_df(df):
if( '割' in df['名前'][0] or
'コース' in df['名前'][0] or
'円' in df['名前'][0] or
'キャンペーン' in df['名前'][0] or
'ツイッター' in df['名前'][0] or
'LINE' in df['名前'][0] or
'日記' in df['名前'][0]):
return False
if(df['年齢'][0] < 15 or 100 < df['年齢'][0]):
return False
if(df['バスト'][0] < 40 or 300 < df['バスト'][0]):
return False
if(df['ウエスト'][0] < 40 or 300 < df['ウエスト'][0]):
return False
if(df['ヒップ'][0] < 40 or 300 < df['ヒップ'][0]):
return False
# すべてのチェックをパスしたらTrueを返す
return True
# 1行分のdataframeに変換する関数
def to_gal_df(gal_infos, prefecture, shop_name, shop_sub_info):
# 1店舗分の女の子のdataframe
gal_df_1shop = pd.DataFrame(
index=[],
columns=['名前', '年齢', '身長',
'バスト', 'カップ', 'ウエスト', 'ヒップ',
'一言説明', '都道府県', '店舗名', '店舗種類']
)
for gal_info in gal_infos:
# 1行分のdataframeを作る
df = pd.DataFrame(
index=[0],
columns=['名前', '年齢', '身長',
'バスト', 'カップ', 'ウエスト', 'ヒップ',
'一言説明', '都道府県', '店舗名', '店舗種類']
)
try:
# split結果の例: ['', '咲歩(さほ)', '34歳/168cm/84(C)-58-87', '【敏感過ぎる身体】', ' 1', '']
gal_info_split = gal_info.text.split('\n')
# 名前の格納
df['名前'][0] = gal_info_split[1]
# 歳、身長、スリーサイズの格納
# split後の例:['34歳', '168cm', '84', 'C', '', '58', '87']
gal_spec = re.split('[/()-]', gal_info_split[2])
df['年齢'][0] = int(re.sub("\\D", "", gal_spec[0]))
df['身長'][0] = int(re.sub("\\D", "", gal_spec[1]))
df['バスト'][0] = int(gal_spec[2])
# カップは書いている女の子と書いていない女の子がいるので処理分岐
if(gal_spec[4] == ''):
df['カップ'][0] = gal_spec[3]
df['ウエスト'][0] = int(gal_spec[5])
df['ヒップ'][0] = int(gal_spec[6])
else:
df['カップ'][0] = '-'
df['ウエスト'][0] = int(gal_spec[3])
df['ヒップ'][0] = int(gal_spec[4])
# 一言説明
df['一言説明'][0] = gal_info_split[3]
### prefecture_infoの処理
df['都道府県'][0] = prefecture_info.text.strip()
### shop_name_infoの処理
df['店舗名'][0] = shop_name_info.text.strip()
### shop_sub_infoの処理
shop_sub_info_split = re.split('[|【]', shop_sub_info.text)
shop_kind = shop_sub_info_split[1].split(' ')
df['店舗種類'][0] = shop_kind[1]
# 女の子のデータと判断したものはdataframeに追加
if(is_valid_df(df)):
gal_df_1shop = gal_df_1shop.append(df)
# 配列に合わないデータになる場合は例外
except:
continue
return gal_df_1shop
# ファイルリストを作る
file_paths = glob.glob('./htmls/*.html')
# 進捗確認用の変数
count_gals = 0
count_shops = 0
num_shops = len(file_paths)
# 空のdataframeを作る
gal_df = pd.DataFrame(
index=[],
columns=['名前', '年齢', '身長',
'バスト', 'カップ', 'ウエスト', 'ヒップ',
'一言説明', '都道府県', '店舗名', '店舗種類']
)
for file_path in file_paths:
# 対象のhtmlファイルからsoupを作成
html = bs4.BeautifulSoup(open(file_path, encoding='utf-8'), 'html.parser')
gal_infos = html.find_all(class_="text") # 女の子のスペックのみを取り出してリストにする
prefecture_info = html.find(class_="logo") # このタグの中に都道府県が書いてある
shop_name_info = html.find(class_="header_shop_title") # このタグの中に店舗名が書いてある
shop_sub_info = html.find("title") # このタグの中に店舗種類が書いてある(人妻デリヘルとか)
# gal_infosから、1店舗分のdataframeを生成
df = to_gal_df(gal_infos, prefecture_info, shop_name_info, shop_sub_info)
#1店舗分のdfをgal_dfのケツに追加。最終的にはgal_dfをファイルに書き出す
gal_df = gal_df.append(df)
count_shops += 1
print( '\r' + '現在 %04d / %04d 店舗目を処理中' % (count_shops, num_shops), end='' )
# 100店舗ごとにgal_dfをファイル書き出し(途中でプログラムをストップしても中間結果が残るように)
if(count_shops % 100 == 0):
gal_df.to_csv("database/gals_database.csv", encoding='utf_8_sig', index=None)
# 最終結果をファイル書き出し
gal_df.to_csv("database/gals_database.csv", encoding='utf_8_sig', index=None)
12~32行目が、記事上部で説明したデータ除外処理を行っている部分になりますね。
今までと同じように、anaconda prompt上で実行(※)します。
(※)anaconda prompt上でsrcフォルダに移動し、以下のコマンドで実行
>python gen_database.py
前回同様、実行時間は4時間くらいかかるので、気長に待ちましょう。
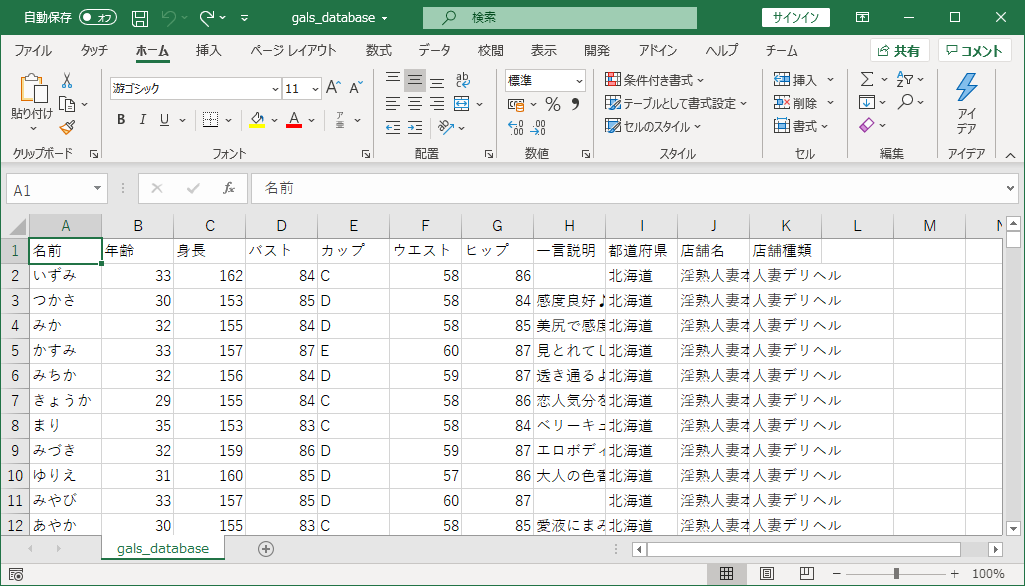
全国のデリヘル嬢をまとめたデータベースが完成!
databaseフォルダを確認しましょう。
csvファイルができているかと思いますので、エクセルなどで開いてみます。
以下のように女の子の情報が羅列されていたらOKです。
30万人以上のデータを1つのファイルにまとめることができました。感動です。
それは、分析に使うためでした。
もっと具体的に言えば、「ウエスト60以上のデリヘル嬢は何割?」とか、
「一番多い源氏名は?」といった疑問を、データベースを使った統計分析によって解決するためです。
そのため、実際はデータベースの解析用プログラムを別途作成してそれらの疑問に答えていくことになります。
そちらも近々アップしようと思いますので、しばしお待ちください。
それではまた!